CI-ICM 论文精读
在 红外图像压缩系列 的前几篇中,我们反复遇到一个核心张力:传统编码器把所有像素或变换系数当作同等重要的信息源来优化码率-失真曲线,但机器视觉任务并不需要这种均匀保真。精读(二)SA-ICM 从空间维度回答了这个问题——用 SAM 边缘 mask 告诉 codec 哪些空间位置更重要。然而 SA-ICM 的操作发生在像素域的训练监督层面,它并没有触及学习式压缩器内部潜空间的结构。
CI-ICM 把同样的追问推进到了特征域。它的出发点是一个看似简单但影响深远的经验观察:在学习式图像压缩器的潜空间表示 \(\mathbf{y}\) 中,不同通道对下游机器任务的贡献差异极大 #Zhang-et-al.-2026。这个观察并不是凭空假设,而是通过一组系统的扰动实验验证得到的。
论文作者以 TransTIC #Chen-et-al.-2023 作为基线 ICM codec,提取其 192 通道的潜空间特征 \(\mathbf{y}\),然后做了四类扰动实验:(a) 逐个通道置零;(b) 按组(每组 24 通道,共 8 组)置零;(c) 向单个通道添加不同强度的随机噪声;(d) 向整组通道添加随机噪声。所有扰动后的特征经解码重建后送入 Faster R-CNN 做 COCO 目标检测,以 mAP@50:95 衡量精度损失 #Zhang-et-al.-2026。
实验结果揭示了两个关键事实。第一,当逐个通道置零时,某些通道被移除后 mAP 几乎不变,而另一些通道被移除后 mAP 急剧下降;按组置零时,组 #1、2、#5 的移除造成显著精度退化,而组0、#3、7 的移除几乎没有影响。第二,添加低强度噪声(范围 \([-0.5, 0.5]\))时精度基本不变,但高强度噪声(范围 \([-1, 1]\))导致部分通道/组的精度大幅下降——这说明通道重要性不仅与"哪个通道"有关,还与"失真强度"有关 #Zhang-et-al.-2026。
核心洞察
潜空间 192 个通道中,大约 32 个通道承载了绝大部分任务关键信息,其余约 160 个通道可以在较大失真下仍保持任务精度。这意味着最优码率分配策略不应该是均匀的,而应该高度不均匀:给少数关键通道更多比特,给多数非关键通道更少比特。
这个发现可以被视为 SA-ICM 思想在通道维度的自然延伸。SA-ICM 在空间维度区分了"边缘区域 vs 纹理区域",CI-ICM 则在特征通道维度区分了"任务关键通道 vs 任务冗余通道"。两者共享同一个底层信念:面向机器的压缩不应追求均匀保真,而应追求任务感知的非均匀资源分配。区别在于 SA-ICM 通过训练监督间接实现这种偏好,而 CI-ICM 则直接在 codec 架构中显式建模通道重要性并据此设计码率分配机制。
论文基本信息
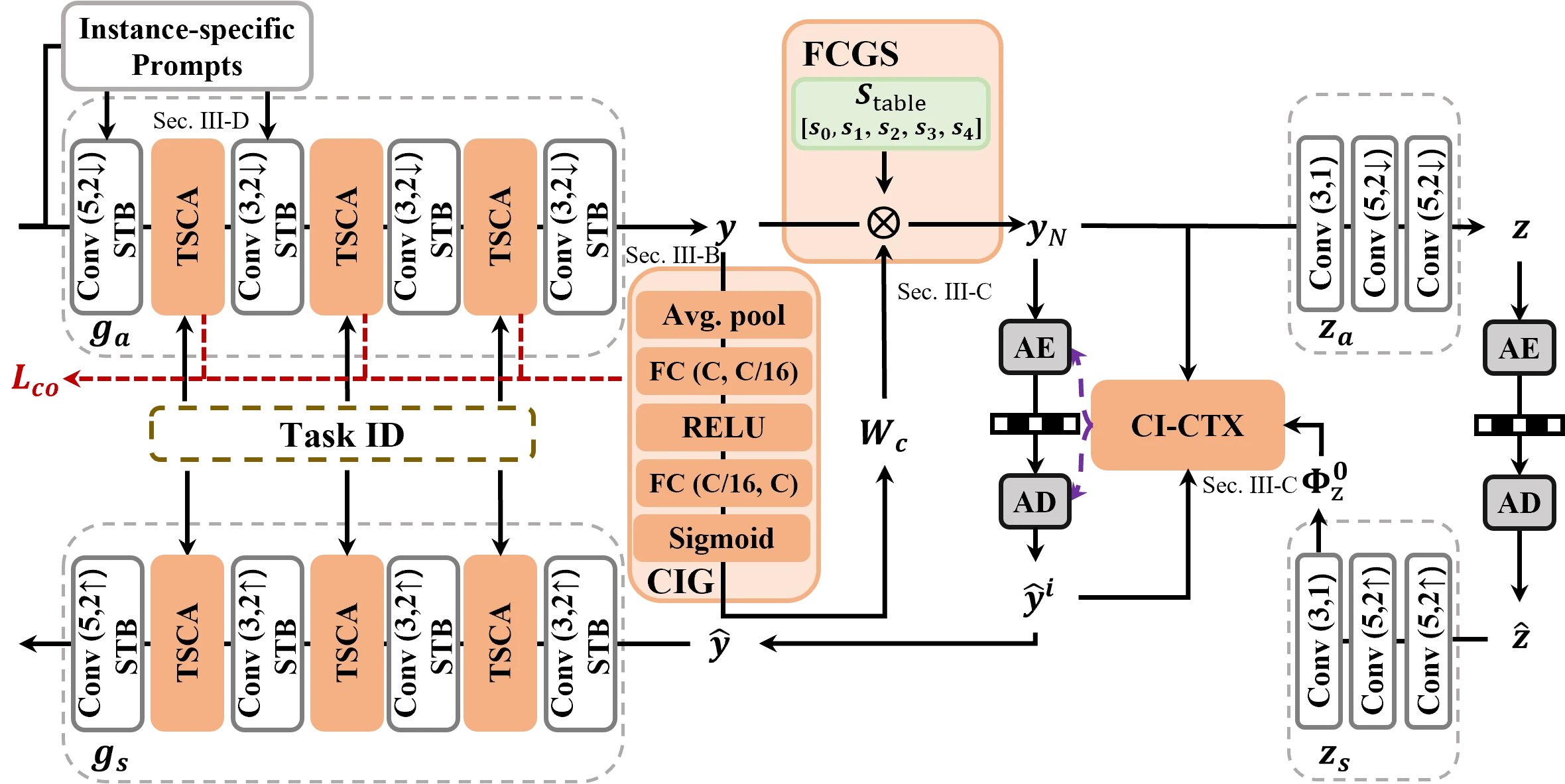
CI-ICM 全称为 Channel Importance-driven Learned Image Coding for Machines,作者为 Yun Zhang、Junle Liu(中山大学深圳校区)、Huan Zhang(广东工业大学)、Zhaoqing Pan(天津大学)、Gangyi Jiang(宁波大学)和 Weisi Lin(南洋理工大学),arXiv 编号 2604.05347,提交于 2026 年 4 月 7 日 #Zhang-et-al.-2026。论文以 TransTIC 为基线骨干,在其上叠加 CIG、FCGS、CI-CTX、TSCA 四个模块,形成完整的通道重要性驱动 ICM 框架。
CI-ICM 的方法可以拆解为四个紧密协作的模块。CIG 负责量化每个通道的重要性;Channel Order Loss 确保编码器输出的特征按重要性降序排列;FCGS 根据排序结果进行不均匀分组和动态范围缩放;CI-CTX 利用分组结构做序列熵编码,让重要组获得更多比特;TSCA 则提供轻量级的任务切换能力。下面逐一展开。
graph LR
A["输入图像 x"] --> B["编码器 g_a"]
B --> C["潜特征 y"]
C --> D["CIG 重要性估计 W_c"]
D --> E["Channel Order Loss"]
C --> F["FCGS 重排序+分组+缩放"]
F --> G["CI-CTX 序列熵编解码"]
G --> H["解码器 g_s"]
H --> I["重建图像 x_hat"]
I --> J["机器视觉任务模型"]
K["TSCA CAB"] -.-> B
K -.-> H
classDef core fill:#2d5a3d,stroke:#4a9,stroke-width:2px,color:#fff
class D,F,G core
2.1 CIG:通道重要性生成模块
CIG(Channel Importance Generation)的结构非常经典:Global Average Pooling (GAP) 后接两层全连接网络,中间用 ReLU 激活,最后用 Sigmoid 输出。输入是潜空间特征 \(\mathbf{y} \in \mathbb{R}^{C \times H \times W}\),输出是一个 \(C\) 维的重要性权重向量 \(\mathbf{W}_c \in [0,1]^C\) #Zhang-et-al.-2026:
CIG 的前向传播
其中 \(\mathcal{M}_c(\cdot)\) 是 GAP + FC + ReLU + FC + Sigmoid 网络,\(\mathbf{W}_c\) 的第 \(i\) 个元素 \(w_i\) 表示第 \(i\) 个通道对机器任务的重要性。
这个结构本质上是 SE-Net #Hu-et-al.-2018 的通道注意力机制,但在这里它的角色不是做特征增强,而是做重要性评估。CIG 的输出 \(\mathbf{W}_c\) 有两个用途:一是直接调制特征 \(\mathbf{y}\),让重要通道的响应更强;二是为后续的分组和排序提供依据。
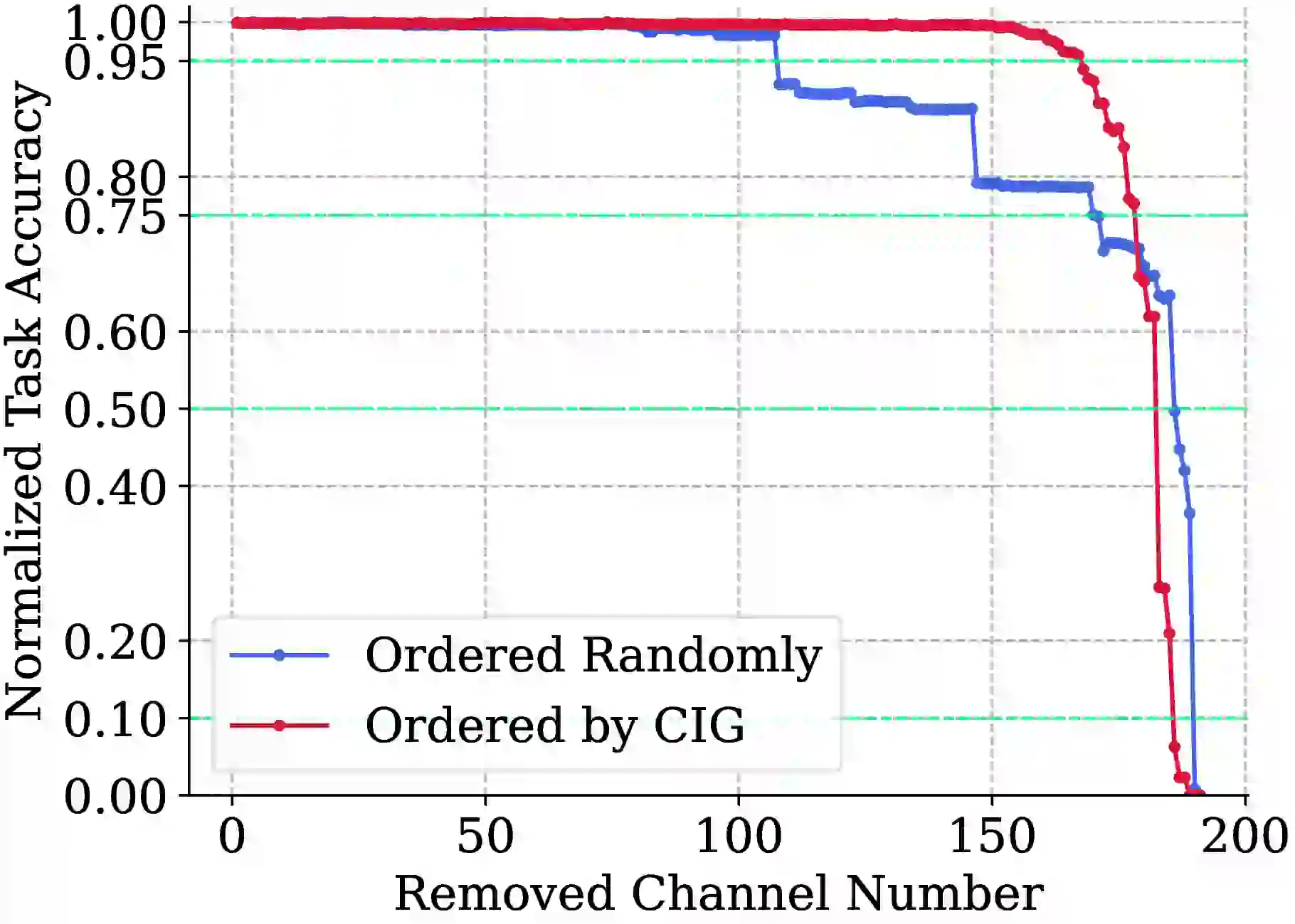
为了验证 CIG 的有效性,论文做了一个通道逐步移除实验。在冻结 TransTIC 其他参数的情况下单独训练 CIG,得到 \(\mathbf{W}_c\),然后按权重从小到大逐步移除通道。结果显示:按 CIG 排序移除时,直到移除约 160 个通道后 mAP 才开始明显下降;而随机排序移除时,移除约 110 个通道后精度就开始退化。这 50 个通道的差距直接证明了 CIG 能够准确识别出哪些通道对任务真正重要 #Zhang-et-al.-2026。
2.2 Channel Order Loss:单调性约束
CIG 给出了重要性权重,但编码器 \(g_a\) 输出的特征通道顺序是随机的。为了让后续的不均匀分组能够正确地把重要通道放进小组、不重要通道放进大组,需要让编码器学会按重要性降序排列通道。
论文设计了 Channel Order Loss \(L_{CO}\),灵感来自单调性损失 #Yang-et-al.-2023。它的逻辑很直观:遍历相邻通道对,如果后一个通道的权重比前一个大(即出现了"逆序"),就把差值累加为惩罚 #Zhang-et-al.-2026:
Channel Order Loss
其中 \(\mathbb{I}(\cdot)\) 是指示函数。当序列严格递减时,\(L_{co}^{\text{CIG}} = 0\);任何逆序对都会产生正惩罚。
同样的 loss 也施加在 TSCA 模块的增强因子 \(\gamma\) 上,记为 \(L_{co}^{\text{TSCA}_k}\)。总 channel order loss 为两者之和:
实验中 \(\varphi_k = 0.1\),\(\varphi_{CIG} = 0.3\)。Fig. 9 展示了训练前后 \(\mathbf{W}_c\) 的变化:训练前通道权重杂乱无章,训练后呈现清晰的降序排列 #Zhang-et-al.-2026。
2.3 FCGS:不均匀分组与缩放
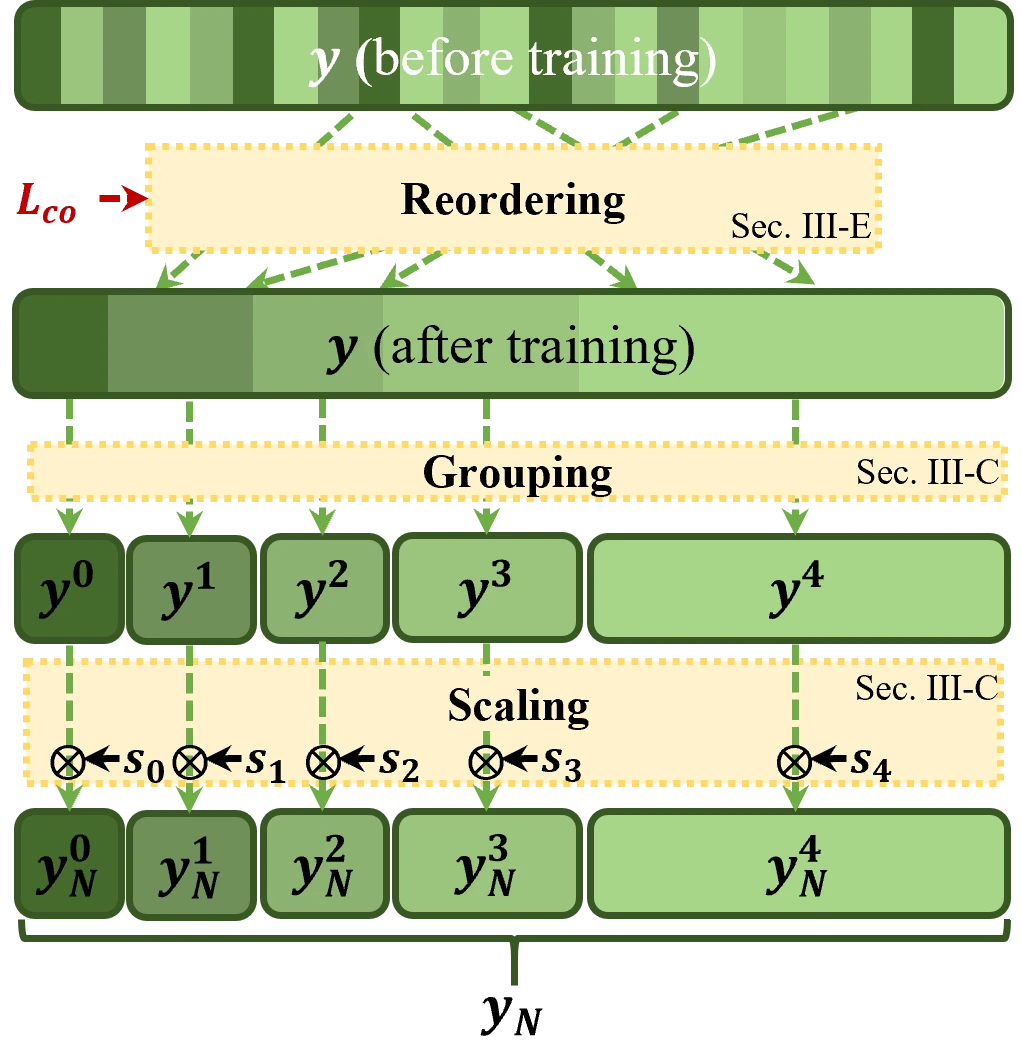
FCGS(Feature Channel Grouping and Scaling)是 CI-ICM 最具工程特色的模块。它基于通道移除实验的发现——192 个通道中约 32 个是关键通道、约 160 个是非关键通道——将排好序的特征分成 5 个大小极不均匀的组 #Zhang-et-al.-2026:
| 组索引 \(i\) | 组大小 \(l_i\) | 缩放因子 \(s_i\) | 含义 |
|---|---|---|---|
| 0(最重要) | 4 | 1 | 最关键通道,不做缩放,保留最高保真度 |
| 1 | 4 | 1.85 | 次关键通道,轻微压缩 |
| 2 | 8 | 2.27 | 中等重要通道 |
| 3 | 16 | 3.71 | 较低重要通道 |
| 4(最不重要) | 160 | \(10^{4.38} \approx 23988\) | 大量冗余通道,极度压缩 |
缩放操作本身很简单:\(\mathbf{y}_N^i = \mathbf{y}^i / s_i\)。除以更大的缩放因子意味着该组特征的动态范围被压缩,量化后占据更少的比特。注意 \(s_0 = 1\) 保证最重要的一组完全不失真(相对于缩放操作而言),而 \(s_4 \approx 23988\) 意味着最不重要的 160 个通道几乎被量化为零 #Zhang-et-al.-2026。
缩放因子的确定过程也很有方法论价值。论文首先初始化缩放表为 \([1, 1, 2, 10, 10^4]\),然后逐个调整每个 \(s_i\),同时固定其他 \(s_j\)(\(j \neq i\)),测量缩放后的先验参数 \(\Phi_{ch}^i\) 与原始先验 \(\Phi_{ch-org}^i\) 之间的 MSE。实验发现每个 \(s_i\) 只影响自己对应组的先验精度,对其他组几乎无影响——这意味着缩放因子之间近似独立,可以逐个优化。最终通过在 COCO2017 验证集上搜索使 mAP@50:95 最大的 \(s_i\),并用二次函数拟合得到最优值 #Zhang-et-al.-2026。
2.4 CI-CTX:通道重要性感知上下文熵编码
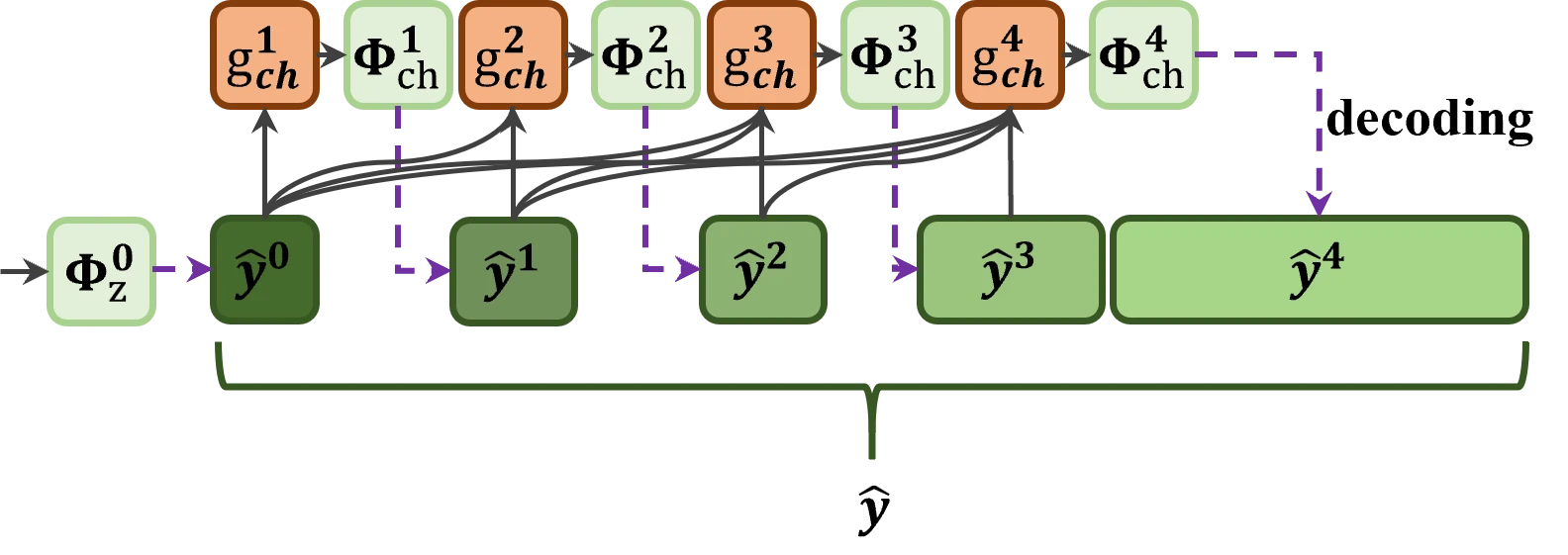
FCGS 完成了分组和缩放,但还需要一个熵模型来实际编码这些不均匀的组。CI-CTX(Channel Importance-based Context)的设计原则是:按重要性顺序依次编码,已解码的重要组作为后续组的上下文先验 #Zhang-et-al.-2026。
具体来说,解码过程是序列化的。第 0 组(最重要的 4 个通道)仅依赖超先验 \(\Phi_z^0\) 解码;第 \(i\) 组(\(i \geq 1\))则同时依赖超先验和前面所有已解码组的上下文 \(\Phi_{ch}^i = g_{ch}^i(\hat{\mathbf{y}}^0, \hat{\mathbf{y}}^1, \ldots, \hat{\mathbf{y}}^{i-1})\):
CI-CTX 的序列化解码
重要组先解码、先建立上下文;后续组利用这些上下文获得更精确的概率估计,从而可以用更少的比特编码。
这里的关键耦合在于:因为 FCGS 把重要通道放进了小组(4、4、8、16),所以前面的组包含的通道数少,每个通道分到的比特自然更多;后面的组包含 160 个通道,但由于有前面组的上下文帮助,概率估计更准,加上缩放因子极大,实际消耗的比特很少。这种"小组高保真 + 大组低保真"的策略正是 CI-ICM 码率分配的核心机制。
在每个组内部,CI-CTX 还使用了并行棋盘格空间上下文模块 #He-et-al.-2022 进一步提升编码效率。
2.5 TSCA:任务特定通道适配
前面的 CIG、FCGS、CI-CTX 都是针对主任务(目标检测)设计的。但实际部署中,同一个压缩码流可能需要服务于不同的下游任务。TSCA(Task-Specific Channel Adaptation)解决的就是这个多任务适配问题 #Zhang-et-al.-2026。
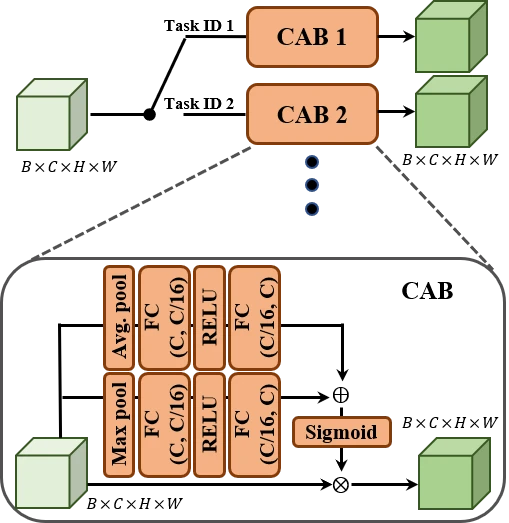
TSCA 的结构是一组并行的 Channel Attention Block (CAB),每个 CAB 专门为一个下游任务训练。当任务确定后,只需激活对应的 CAB,其他 CAB 不参与推理。每个 CAB 内部使用 Global Max Pooling + Global Average Pooling 提取通道的最大值和均值统计量,经共享的两层 FC 网络后求和并通过 Sigmoid 生成通道增强因子 \(\gamma_i^{\text{TSCA}_k}\),再通过逐通道乘法增强特征。
TSCA 的轻量化体现在两个方面。第一,它只在 Stage 3 训练,此时 CI-ICM 的所有其他参数都冻结,只更新 CAB 的参数,训练仅需 10 个 epoch。第二,新增一个任务只需要训练一个新的 CAB,不需要重新训练整个 codec。这使得 CI-ICM 在实际部署中可以灵活扩展任务支持,而不必为每个任务从头训练一个完整的压缩模型 #Zhang-et-al.-2026。
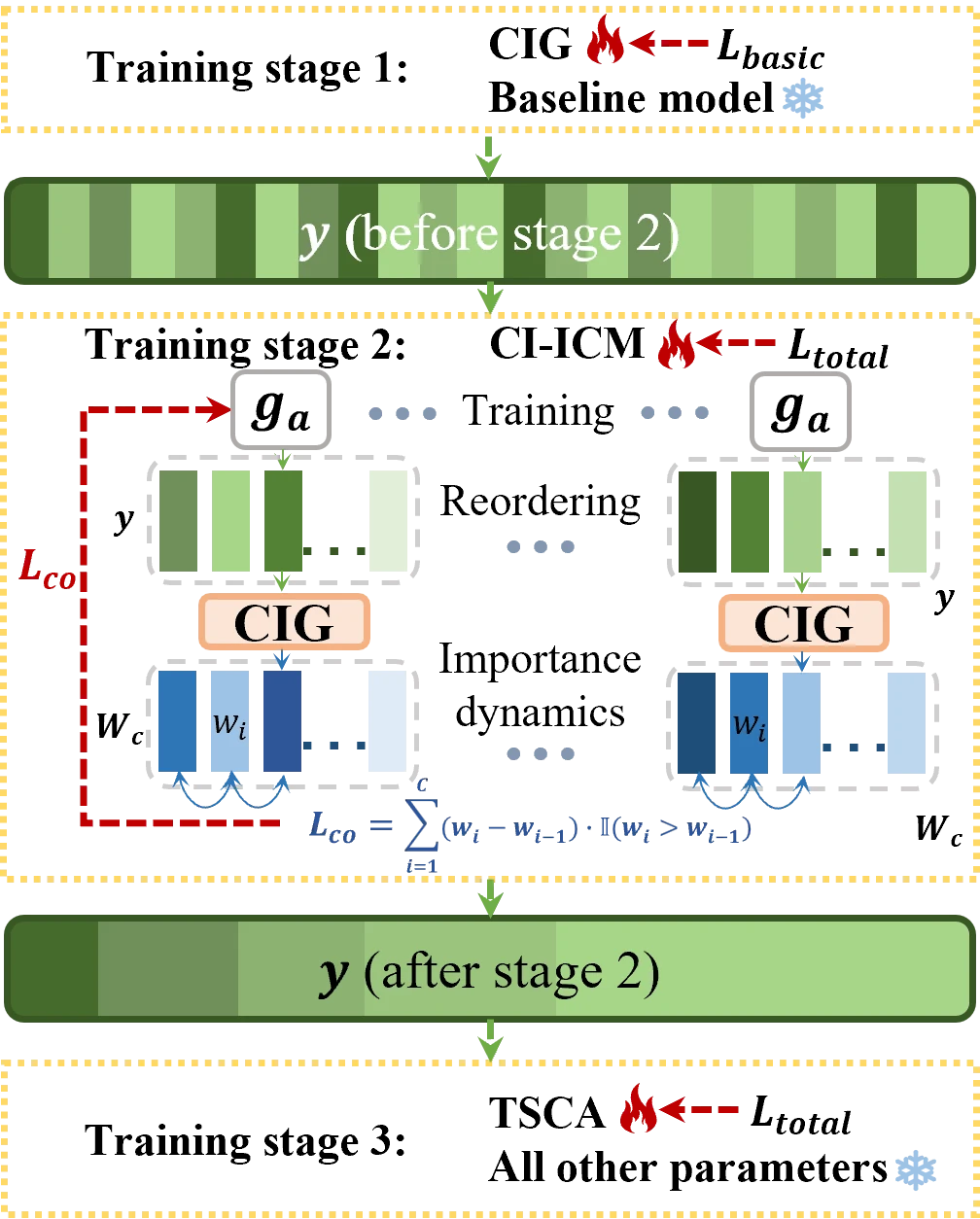
三阶段训练流程
Stage 1:冻结 TransTIC 基线,单独训练 CIG 模块,建立稳定的通道重要性估计器。使用 \(L_{basic}\) 作为损失。
Stage 2:端到端联合训练整个 CI-ICM 框架(包括编码器重排序、FCGS、CI-CTX),使用 \(L_{total}\) 作为损失,训练 30 个 epoch,学习率 \(10^{-4}\),batch size 12。损失权重 \(\varphi_k = 0.1\)(TSCA)、\(\varphi_{CIG} = 0.3\)。
Stage 3:冻结所有参数,仅训练 TSCA 中的 CAB,训练 10 个 epoch,学习率 \(10^{-4}\),batch size 32。为新任务添加 CAB 时也只需执行此阶段。
四个码率点通过 Lagrange 乘子 \(\lambda \in \{2, 1, 0.5, 0.2\}\) 控制,每个 \(\lambda\) 训练一个独立模型。
2.6 训练配置披露
| 配置项 | 论文披露内容 | 状态 |
|---|---|---|
| 训练数据集与规模 | COCO2017 训练集(约 118k 图像) | 论文披露 |
| 验证/测试集 | COCO2017 验证集(5,000 图像) | 论文披露 |
| 训练硬件 | NVIDIA GeForce RTX 3090 GPU | 论文披露 |
| 软件框架 | PyTorch | 论文披露 |
| 初始化 | TransTIC 预训练 checkpoint | 论文披露 |
| 优化器 + 学习率 | 未明确说明优化器;lr = \(10^{-4}\) | 部分披露 |
| Batch size + Epoch | Stage 1/2: batch 12, 30 epochs;Stage 3: batch 32, 10 epochs | 论文披露 |
| 码率控制 | \(\lambda \in \{2, 1, 0.5, 0.2\}\),每码率一个模型 | 论文披露 |
| Channel order loss 权重 | \(\varphi_k = 0.1\),\(\varphi_{CIG} = 0.3\) | 论文披露 |
| 训练时长 | 未明确给出总时长 | 未披露 |
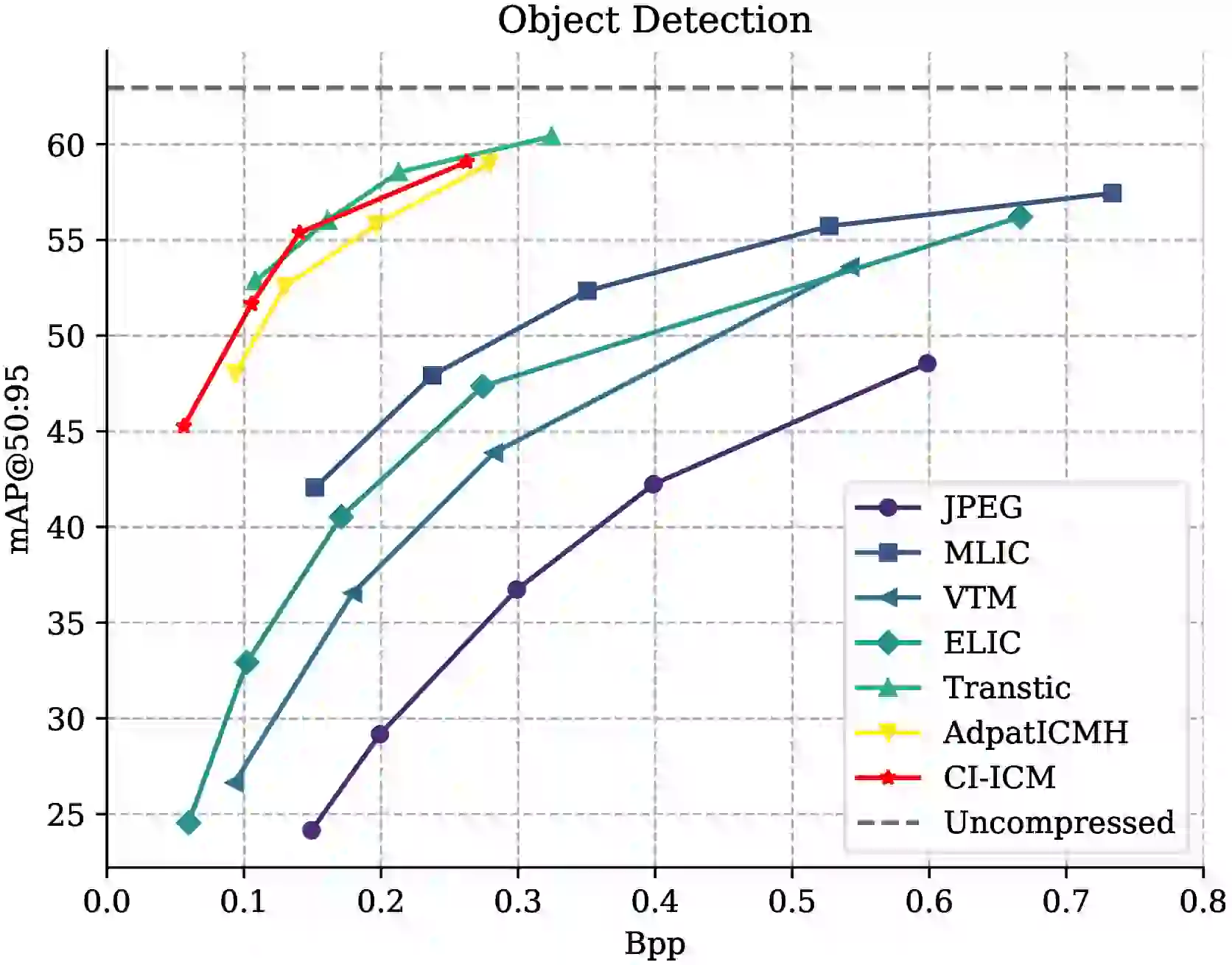
3.1 主实验:目标检测与实例分割
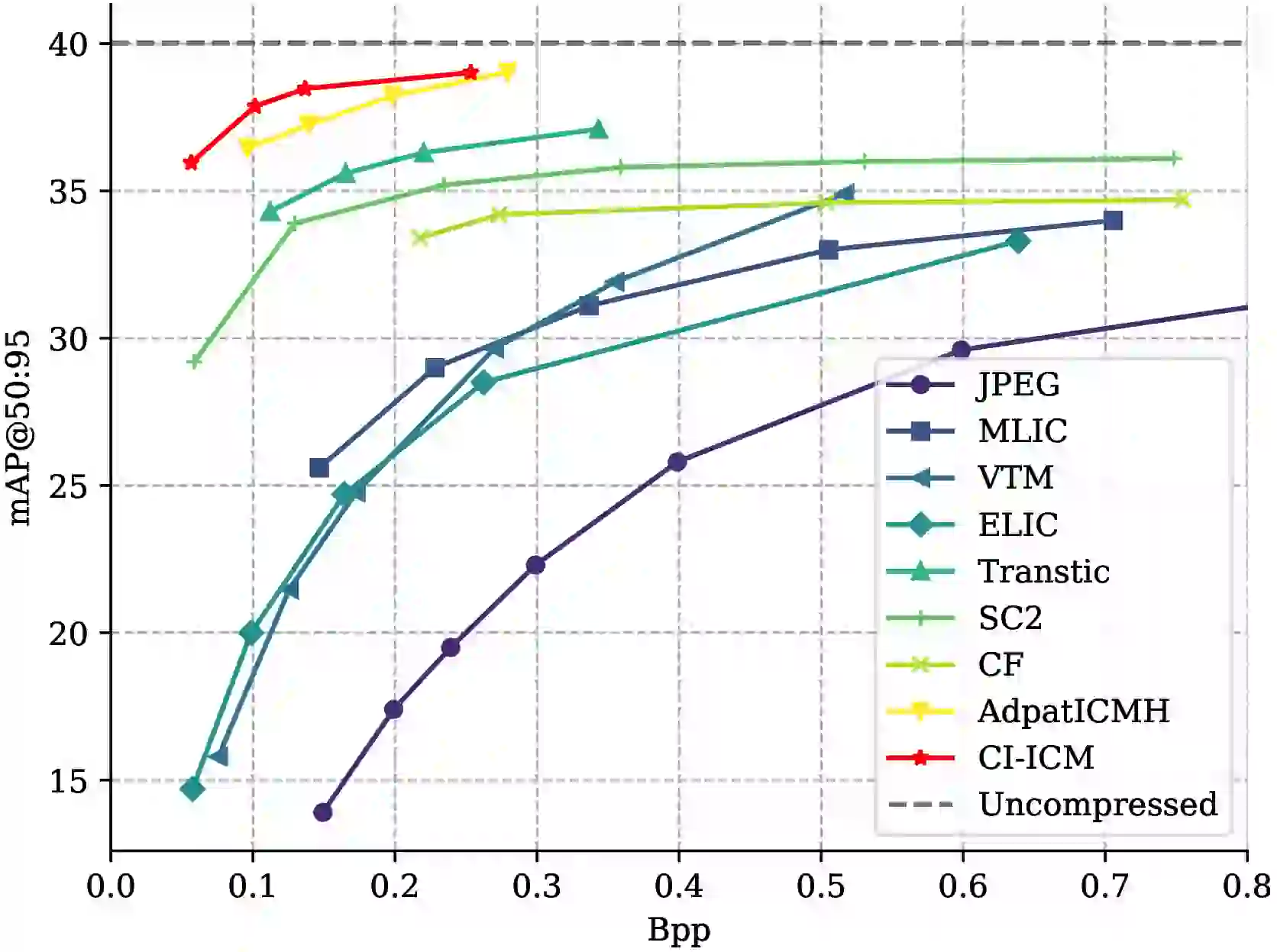
CI-ICM 的主实验在 COCO2017 数据集上进行,目标检测使用 Faster R-CNN(ResNet-50 backbone),实例分割使用 Mask R-CNN(ResNet-50 backbone)。对比基线包括人眼导向编码(JPEG2000、VTM-23.13、ELIC、MLIC)和 ICM 方法(SC2、CF、TransTIC、AdaptICMH)。评价指标为 BD-mAP@50:95、BD-mAP@50、BD-mAP@75,以 ELIC 为锚点 #Zhang-et-al.-2026。
| 编码方案 | BD-mAP@50:95 (检测) | BD-mAP@50 (检测) | BD-mAP@75 (检测) |
|---|---|---|---|
| JPEG2000 | -6.80 | -9.93 | -7.73 |
| VTM-23.13 | +0.17 | -0.66 | +0.51 |
| MLIC | +1.13 | +1.54 | +1.42 |
| CF | +3.78 | +2.91 | +3.56 |
| SC2 | +8.75 | +10.35 | +8.70 |
| TransTIC | +9.86 | +12.75 | +11.54 |
| AdaptICMH | +13.13 | +16.85 | +15.21 |
| CI-ICM | +16.25 | +20.92 | +18.49 |
CI-ICM 在目标检测上相对 ELIC 取得 BD-mAP@50:95 +16.25%,相对当时 SOTA 的 AdaptICMH 高出 3.12 个百分点。在实例分割上,CI-ICM 取得 BD-mAP@50:95 +13.72%,相对 AdaptICMH 高出 2.44 个百分点 #Zhang-et-al.-2026。
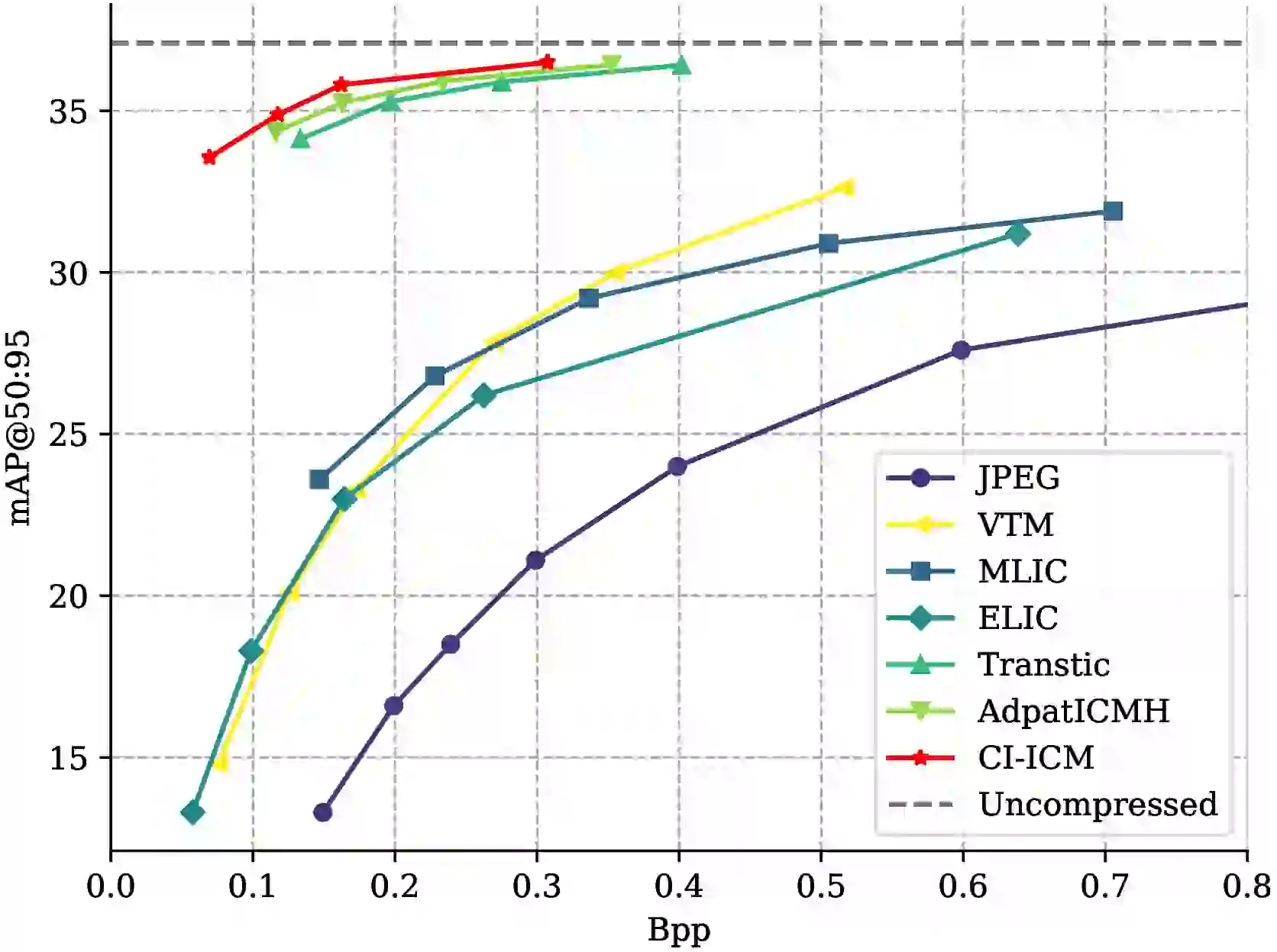
| 编码方案 | BD-mAP@50:95 (分割) | BD-mAP@50 (分割) | BD-mAP@75 (分割) |
|---|---|---|---|
| JPEG2000 | -5.97 | -9.15 | -6.79 |
| VTM-23.13 | +0.54 | +0.17 | +0.56 |
| MLIC | +1.23 | +1.65 | +1.30 |
| TransTIC | +10.21 | +13.38 | +11.54 |
| AdaptICMH | +11.28 | +15.22 | +12.59 |
| CI-ICM | +13.72 | +19.03 | +15.24 |
值得注意的是,CI-ICM 的 CIG 权重、FCGS 和 CI-CTX 都是基于目标检测任务训练的,实例分割仅在 Stage 3 通过 TSCA 微调。即便如此,它在分割任务上仍然大幅领先所有基线,说明通道重要性的排序具有一定的跨任务鲁棒性。
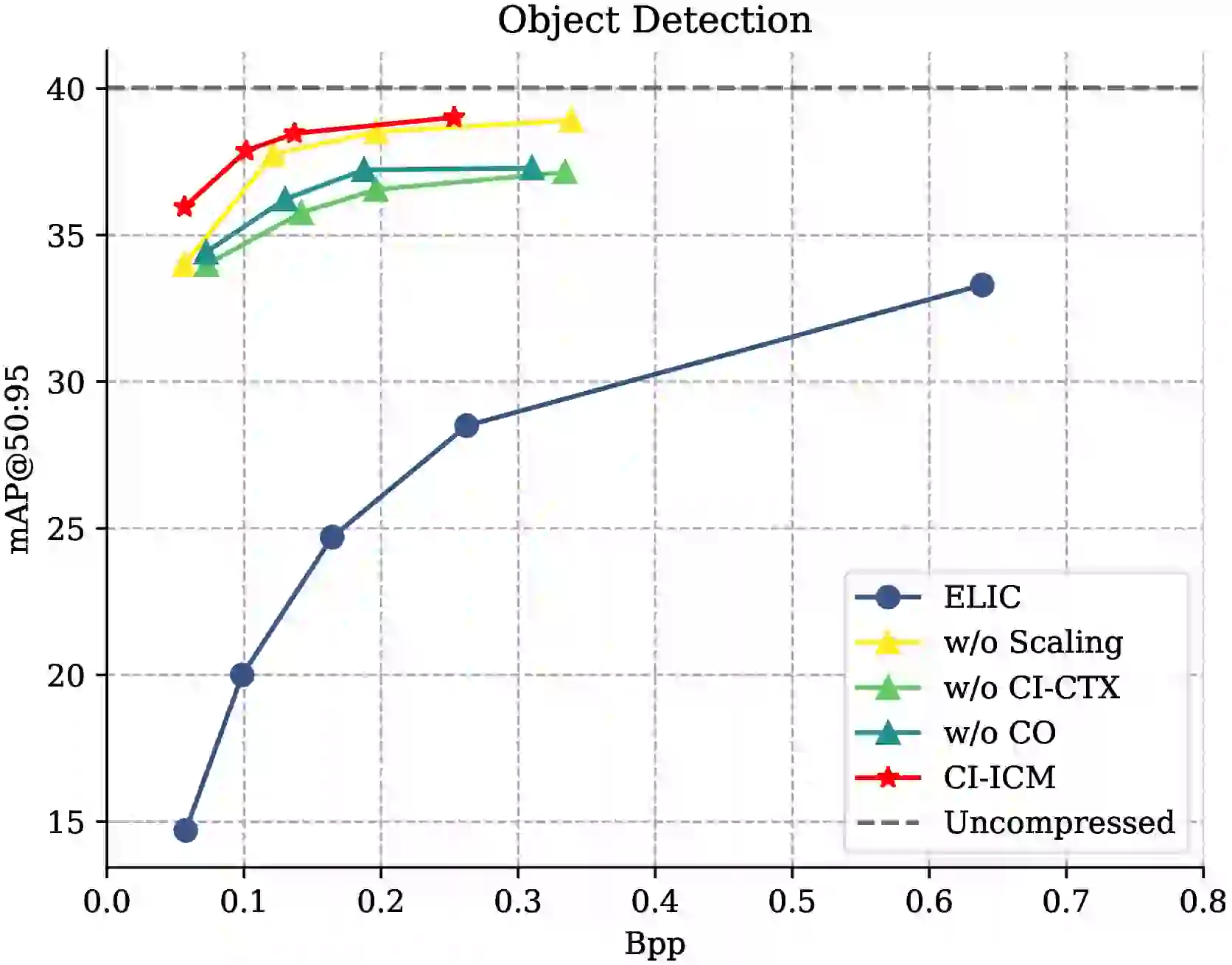
3.2 消融实验
论文的消融实验系统地验证了每个模块的贡献。以目标检测 BD-mAP@50:95 为例 #Zhang-et-al.-2026:
| 消融设置 | BD-mAP@50:95 (检测) | 相对完整版下降 | BD-mAP@50:95 (分割) | 相对完整版下降 |
|---|---|---|---|---|
| w/o Scaling(去掉缩放) | +14.57 | -1.68 | +12.65 | -1.07 |
| w/o CI-CTX(去掉分组+上下文) | +11.84 | -4.41 | +10.25 | -3.47 |
| w/o CO(去掉通道排序) | +12.74 | -3.51 | +11.29 | -2.43 |
| CI-ICM 完整版 | +16.25 | — | +13.72 | — |
三个消融结论清晰:CI-CTX(含分组)的贡献最大(-4.41%),说明序列熵编码和不均匀分组是码率分配的核心机制;通道排序的贡献次之(-3.51%),验证了"先排好序才能正确分组"的逻辑链;缩放的贡献最小但仍显著(-1.68%),表明动态范围调整是对分组策略的有效补充。
TSCA 的消融则以"匹配 vs 不匹配"模式对比。当使用为目标任务训练的 CAB(Matched)时,检测 BD-mAP@50:95 为 +16.25%;当错误地使用为另一任务训练的 CAB(Unmatched)时,降至 +12.67%。分割任务上也观察到类似差距(+13.72% vs +12.78%)。这说明 TSCA 的任务适配确实有效,但不匹配模式下仍有显著增益(相对 ELIC),表明 CI-ICM 的基础通道重要性排序本身就具有跨任务泛化能力 #Zhang-et-al.-2026。
3.3 跨骨干与跨数据集泛化
泛化实验全部使用预训练的 CI-ICM 模型,不做任何重训或微调。结果如下 #Zhang-et-al.-2026:
| 设置 | BD-mAP@50:95 | 备注 |
|---|---|---|
| COCO + ResNet-101 检测 | +13.85 | 换骨干(原训练用 ResNet-50) |
| Pascal VOC 2012 + ResNet-50 检测 | +17.52 | 换数据集 |
| COCO + ResNet-101 分割 | +11.33 | 换骨干 |
| Cityscapes + ResNet-50 分割 | +9.07 | 换数据集 |
在所有四种泛化设置下,CI-ICM 均保持对所有基线的领先。特别是 Pascal VOC 上的 +17.52% 甚至高于 COCO 原测试集上的 +16.25%,这可能反映了 VOC 数据集的物体类别更少、通道重要性的集中效应更明显。Cityscapes 上的 +9.07% 相对较低,可能与城市场景的复杂背景结构有关——CI-ICM 在 COCO 上学到的通道重要性排序未必完美迁移到语义分割主导的场景。
3.4 计算复杂度
| 编码方案 | 编码时间 (s) | 解码时间 (s) | FLOPs (G) | 参数量 (M) |
|---|---|---|---|---|
| ELIC | 2.722 | 0.124 | 871.4 | 31.7 |
| MLIC | 2.133 | 0.203 | 1317.8 | 116.5 |
| TransTIC | 2.311 | 0.175 | 529.9 | 9.0 |
| AdaptICMH | 2.166 | 0.149 | 352.7 | 7.8 |
| CI-ICM | 2.288 | 0.167 | 565.1 | 15.7 |
CI-ICM 的参数量为 15.7M,远低于 ELIC(31.7M)和 MLIC(116.5M),略高于 TransTIC(9.0M)和 AdaptICMH(7.8M)。FLOPs 为 565G,与 TransTIC 相当。编码时间 2.29s、解码时间 0.17s(RTX 3090,1024x1024 图像),在同类方法中处于中等水平。总体来看,CI-ICM 以适度的计算开销换取了显著的编码性能提升 #Zhang-et-al.-2026。
CI-ICM 的实验全部在可见光 COCO 数据集上进行,但其核心思想——"潜空间中并非所有通道对下游任务同等重要"——对红外轮廓压缩有直接的启发意义。不过,迁移这条路线需要正视几个关键障碍。
4.1 识别红外潜空间中的"轮廓关键通道"
CI-ICM 的通道移除实验可以直接在红外图像上复现。具体做法是:用一个在红外数据上训练的 LIC 模型提取潜空间特征,然后逐通道/逐组施加扰动,测量对红外目标检测或轮廓提取任务的影响。如果红外潜空间中同样存在少数关键通道承载大部分轮廓信息的现象,那么 FCGS 的不均匀分组策略就可以直接应用。
但有一个根本差异需要注意:可见光图像的潜空间通常有丰富的纹理信息和语义层次,192 个通道中可能有明确的"语义通道"和"纹理通道"之分;红外图像的纹理远少于可见光,潜空间的通道可能更多地编码热辐射强度和梯度信息,通道重要性的分布模式可能更加弥散或呈现不同的聚集结构。这需要实证验证,不能简单假设 COCO 上的 32/160 分割比例适用于红外。
4.2 FCGS 不均匀分组用于轮廓 vs 背景通道
如果能在红外潜空间中识别出"轮廓关键通道"和"背景通道",FCGS 的设计思路可以调整为:将轮廓关键通道放入小组(高保真),背景通道放入大组(低保真)。这与 SA-ICM 的空间域边缘优先策略形成了互补——SA-ICM 在像素域告诉 codec "哪里重要",FCGS 在特征域告诉 codec "哪些通道重要"。两者结合可能产生更强的效果。
一个具体的技术设想是:先用 SA-ICM 的边缘监督训练一个红外 LIC 基线,再在这个基线上叠加 CIG 和 FCGS,让通道重要性排序反映"对轮廓保真的贡献"而非"对通用检测的贡献"。这需要修改 CIG 的训练目标和 channel order loss 的监督信号。
4.3 TSCA 用于轮廓保持 vs 纹理保持模式切换
TSCA 的多任务适配机制在红外场景中有一个天然的应用场景:同一台红外相机可能需要在"轮廓保持模式"(用于目标识别)和"温度保真模式"(用于测温/热分析)之间切换。两种模式对潜空间通道的优先级完全不同——前者关注梯度和形状通道,后者关注绝对强度通道。如果能为每种模式训练一个 CAB,就可以在不更换 codec 的情况下实现模式切换。
4.4 前置障碍:学习式压缩在单通道红外上的负结果
然而,在讨论如何迁移 CI-ICM 之前,必须正视 系列正文 中提到的一个关键事实:现有学习式压缩方法在单通道红外图像上的表现不如 JPEG2000。这是因为大多数 LIC 模型是在 RGB 自然图像上设计和训练的,其归纳偏置(如三通道颜色相关性、纹理统计、语义层次)不适配红外的单通道热辐射统计。
先修条件
在将 CI-ICM 应用于红外之前,需要先解决"红外专用 LIC 基线"的问题。这可能需要引入红外特定的归纳偏置,例如热辐射物理约束、单通道空间统计建模、或基于红外数据集的预训练。只有当基线 LIC 在红外上达到至少与 JPEG2000 可比的性能时,在其上叠加 CIG/FCGS/CI-CTX 才有意义。否则,通道重要性分析可能只是在一个人眼导向的、不适合红外的潜空间上做无用功。
因此,CI-ICM 对红外轮廓压缩的价值目前更多体现在方法论范式层面而非直接可用的技术方案。它告诉我们:一旦有了合适的红外 LIC 基线,下一步应该做的不是继续改进整体架构,而是先做通道扰动实验,理解红外潜空间的信息分布结构,再据此设计不均匀的码率分配策略。
至此,红外图像压缩系列的五篇论文精读全部完成。它们从不同角度逼近同一个核心问题:如何在有限码率下保留对下游任务真正重要的信息。
五篇精读构成了两条交织的技术线。第一条是传统 vs 学习式:Huf-RLC 代表传统编码在红外场景下的精细化适配,后四篇则代表学习式压缩的不同切入点。第二条是空间 vs 特征:SA-ICM 在像素空间做边缘优先,CI-ICM 在特征空间做通道优先,FreqKD 在频域做高低频分离,AnyThermal 在跨模态空间做信息迁移。
对于红外轮廓压缩这个具体目标,最有直接参考价值的是 SA-ICM(空间边缘监督)和 CI-ICM(通道重要性范式)的结合。前者提供了"什么是轮廓相关信息"的训练信号,后者提供了"如何在 codec 内部差异化对待不同信息"的架构模板。但正如第四章所述,两者的有效迁移都依赖于一个尚未解决的前置问题:构建真正适配红外统计特性的 LIC 基线。
参考来源
- Zhang, Y., Liu, J., Zhang, H., Pan, Z., Jiang, G., & Lin, W. (2026). CI-ICM: Channel Importance-driven Learned Image Coding for Machines. arXiv:2604.05347. arXiv
- Chen, Z. et al. (2023). TransTIC: Prompt Tuning for Image Coding for Machines. arXiv. (CI-ICM 的基线骨干)
- Hu, J., Shen, L., & Sun, G. (2018). Squeeze-and-Excitation Networks. CVPR 2018. arXiv
- He, D. et al. (2022). Checkerboard Context Model for Efficient Learned Image Compression. ICIP 2022. (CI-CTX 中使用的空间上下文模块)
- Yang, R. et al. (2023). Monotonicity-constrained Neural Networks for Channel Ordering. (Channel Order Loss 的灵感来源)
- Shindo, T., Yamada, K., Watanabe, T., & Watanabe, H. (2024). Image Coding for Machines with Edge Information Learning Using Segment Anything. IEEE ICIP 2024 / arXiv:2403.04173. arXiv
- Li, Y. et al. (2024). AdaptICMH: Modulation Adapter for Image Coding for Machines. (CI-ICM 的主要对比方法之一)
- Liu, J., Sun, H., & Katto, J. (2023). Learned Image Compression with Mixed Transformer-CNN Architectures (ELIC). CVPR 2023. arXiv
- Ren, S., He, K., Girshick, R., & Sun, J. (2015). Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks. NeurIPS 2015. arXiv
- He, K., Gkioxari, G., Dollar, P., & Girshick, R. (2017). Mask R-CNN. ICCV 2017. arXiv
- Lin, T.-Y. et al. (2014). Microsoft COCO: Common Objects in Context. ECCV 2014. arXiv